
物联网(IoT)代表了一组现实世界中的“事物”,它们通过网络相互通信,可以与其他设备和服务进行通信。每个“事物”都能够捕获有关其自身或其环境的数据,甚至可能会对这些数据进行一些有限的计算。物联网(IoT)的最终目标是与物理世界无缝集成的大型智能设备网络。
物联网还因其巨大的商业价值而受到关注,并在运输、医疗设备、工业设备等的各行各业中得到了广泛应用。在本文中,将介绍与物联网IoT相关的数据科学问题之一:预测性维护(Predictive maintenance)。
I. 预测性维护介绍
不管在工业、医疗、汽车等其他行业中,设备故障是一个很棘手问题。传统上,解决这些问题的策略是定期进行预防性维护。这些时间表往往非常保守,通常基于行业专家的判断或操作员的经验。 这样往往要花费很高的维护成本,并且很难适应高度复杂或不断变化的工业场景。
物联网(IOT)和数据科学技术的结合,可以提供出一套有效的解决方案。当设备装有传感器并联网传输该传感器数据时,可以通过设备传来的数据,利用数据科学技术,实时诊断问题。并且可以预测各个单元设备的未来运行状况,从而实现按需维护。这种称为预测性(或基于条件的)维护的策略。
II. 探索预测性维护
为了更好地说明实际的预测性维护,这里使用并探究 NASA 于2008年发布的涡扇发动机退化模拟数据集。其中每个发动机都有21个传感器,这些传感器在运行时收集与发动机状态有关的不同测量值每列是不同的变量,并记录为多个多元时间序列。
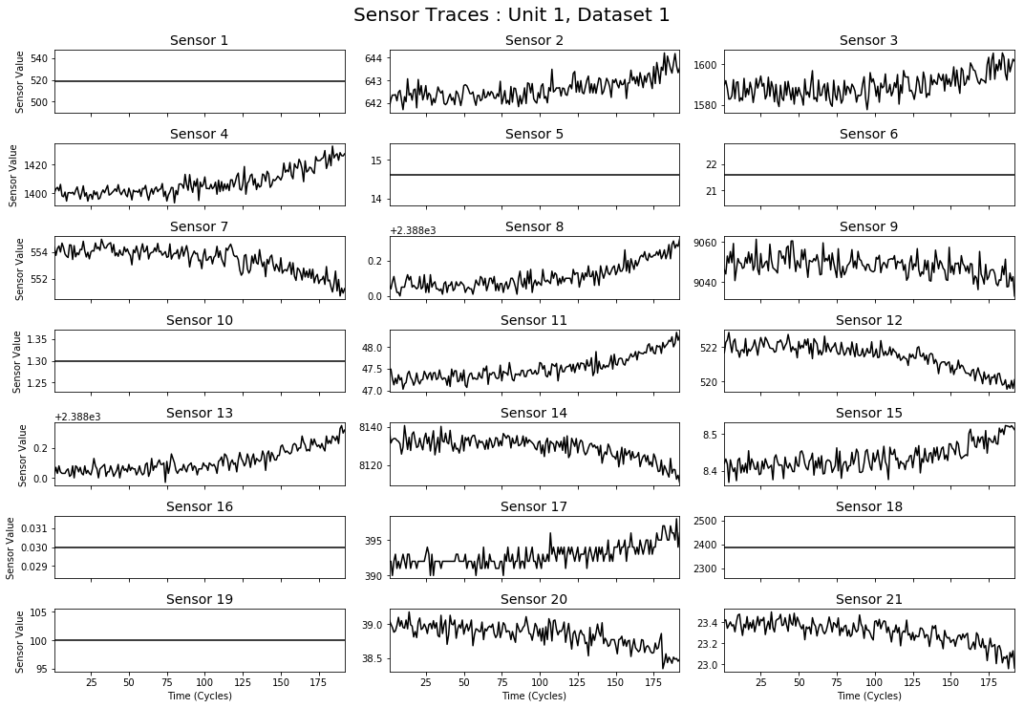
上图显示了数据集中某个发动机引擎上传感器的读数。每个传感器都测量有关发动机物理状态的信息,例如温度、风扇速度等。从图中可以看出,有些传感器信号数据的噪声(波动)很大,并且会随时间增加或减少。而有些传感器信号数据则根本没有变化。在现实中,每个传感器测量值都会有噪声,并可能包含许多缺失或无用的值。
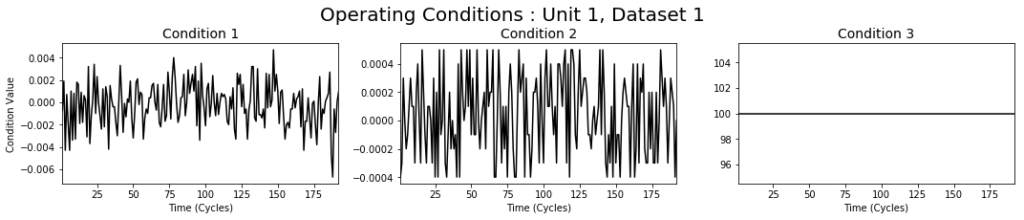
除了内部传感器的测量值之外,物联网系统中的每个设备单元还可以测量有关外界或其运行状况环境的信息。在数据集中,每台发动机在略有不同的条件下运行,其特征是随时间变化的三个维度(例如海拔或外部气压)。下图显示了相同发动机在不同运行条件下,随时间变化的测量值。
数据集包括训练集和测试集。在这两种情况下,每个发动机都以不同(未知)的磨损状态启动,并允许其运行直至故障。在训练集中,在直到故障时刻的所有时间步长上记录所有传感器的测量值。

上图显示了从训练集中随机抽取的10个发动机样本的所有21个传感器随时间变化的测量数据。每个子图包含10条线(每个引擎一条)。从该图可以明显看出,也许由于它们的初始条件不同,每个引擎的寿命和故障模式也略有不同。而且每个引擎的时间进度与其他引擎的进度都不完全一致。
因为在训练集中,已经给出了每个引擎何时会发生故障,所以我们可以在每个时间步长计算一个“发生故障之前的时间”值,该值定义为该时间引擎的使用寿命减去其总寿命。这个数字是每个引擎故障倒计时的一种,它使我们能够将不同引擎的数据对齐到一个公共端点。下图显示了来自与上面图中相同引擎的传感器通道,现在针对它们在发生故障之前的时间进行绘制。每个引擎现在都在同一时刻(t = 0)结束,如红线所示:
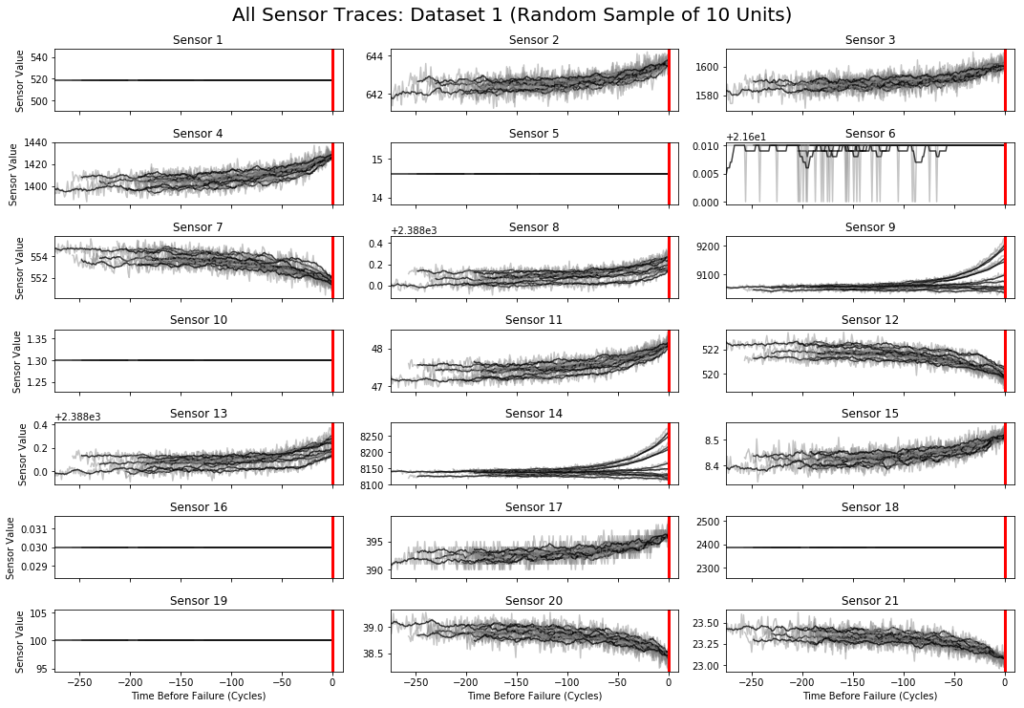
以这种方式对齐数据可以使我们观察到一些模式。例如,我们看到一些传感器测量值在发生故障之前就呈现一直上升或下降,而其他传感器(例如传感器14)在不同的发动机上表现出不同的故障行为。这说明了许多预测性维护问题的一个微妙而重要的方面:故障通常是不同过程的融合,现实世界中的“事物”可能会表现出多种故障模式。
IV. 预测的挑战
 测试集与训练集相似,不同之处在于每个引擎的测量在失效之前会被截断一些(未知)时间,也就是测试数据集没有提供最终的失效时间。上图显示了要预测的任务。在一段时间内观察发动机的传感器测量值和运行状况(图中为133个循环)之后,面临的挑战是预测发动机在故障之前将继续运行的时间。该数字由图中的红色区域表示,称为发动机的剩余使用寿命(RUL)。需要注意的是,对于测试集中的引擎,我们无法像训练集中那样将传感器读数与“发生故障之前的时间”对齐,因为在测试集中不知道引擎何时会发生故障。
测试集与训练集相似,不同之处在于每个引擎的测量在失效之前会被截断一些(未知)时间,也就是测试数据集没有提供最终的失效时间。上图显示了要预测的任务。在一段时间内观察发动机的传感器测量值和运行状况(图中为133个循环)之后,面临的挑战是预测发动机在故障之前将继续运行的时间。该数字由图中的红色区域表示,称为发动机的剩余使用寿命(RUL)。需要注意的是,对于测试集中的引擎,我们无法像训练集中那样将传感器读数与“发生故障之前的时间”对齐,因为在测试集中不知道引擎何时会发生故障。
从本质上讲,以这种方式估算RUL成为物联网中预测性维护核心问题:具体来说主要任务是预测每个“事物”何时会失效,因为它提供了有关其寿命,当前状况,过去的操作历史以及记录类似的其他“事物”的历史。在生产中,这种预测模型可用于实时监控和警报,并进行一些机载计算,甚至可以使设备安排自己的维护。
V. 错误预测的代价
评估预测性维护模型时,最重要的考虑因素之一是错误预测的成本。要了解原因,可以想象我们已经根据上面的数据训练了一个模型,现在正在生产中使用它来告诉我们何时应该将飞机投入维修。如果我们的模型恰好低估了引擎真实的RUL,会导致维护服务的时间过早。如果我们的模型反而高估了真实的RUL会发生什么?在这种情况下,我们可能会让性能下降的飞机继续飞行,并冒着灾难性的发动机故障的风险。显然,这两个结果的成本并不相同。
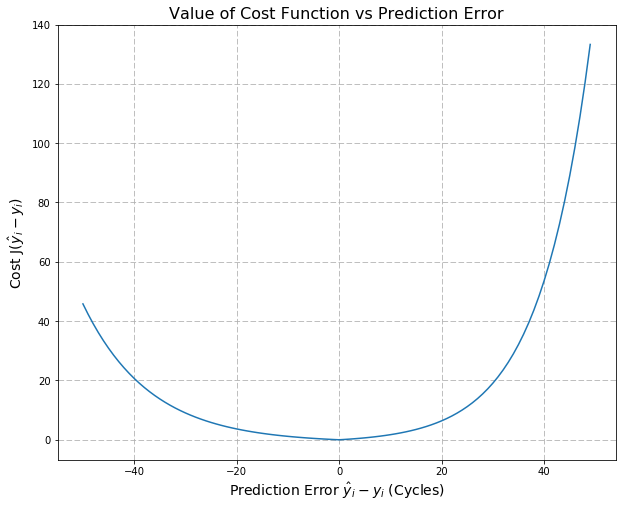 为了捕获与不同类型的错误预测相关的不同成本,一种方法是使用非对称成本函数进行评估(如上图)。通常此类函数会应用于模型的输出(在本例中为RUL预测),并返回与该模型的预测相关联的总“惩罚”。在评估多个模型时,首选成本最低的模型。
为了捕获与不同类型的错误预测相关的不同成本,一种方法是使用非对称成本函数进行评估(如上图)。通常此类函数会应用于模型的输出(在本例中为RUL预测),并返回与该模型的预测相关联的总“惩罚”。在评估多个模型时,首选成本最低的模型。
在文献中建议的一个好的选择是使用下面的评估函数:
![]()
其中N是要评估的引擎总数,yhat_i和y_i分别是引擎i的RUL的预测值和真实值。此函数对真实RUL的高估的惩罚要比低估的惩罚更多。
VI. What next?
可以很容易地看出,上述NASA提供的数据集是用于试验和评估预测性维护问题的理想测试数据。在以后的文章中,我们将更深入地研究数据集,并说明解决RUL估计问题的一些建模方法。
